curl: (56) Recv failure: Connection reset by peer 分析解决过程




悲催的事情
今天下午2点多(时间发生故障的时间是14:14 ,反馈时间却是:14:25 )收到运营推广部门同事告知,网站打不开了,这个烦呀,怎么会打不开了,由于以前的系统有问题,都重新写了,切换到新的系统上面了,打不开就直接报错了,报错页面如下

分析过程
找到错误日志
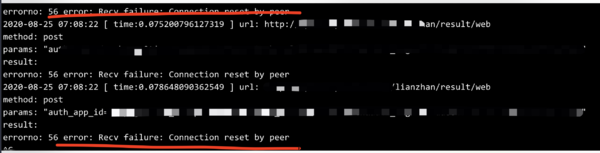
出现错误不可怕,这一点我们必须第一时间明确,千万不要担心,担心解决不了任何问题。 对我们最有帮助的就是各种业务日志。通过查阅日志得出如下的错误,当时出现了大量的错误日志
curl: (56) Recv failure: Connection reset by peer
如下是我们的业务架构图
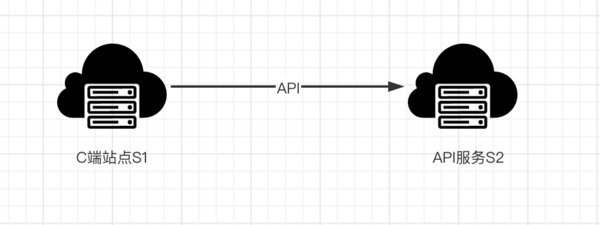
可以我们S1 通过API 接口 访问 S2 , 我们的错误日志就是在S1上面发现的,因为我们所有的http请求都是通过一个类发出去的,会进行文件日志存储,大致代码如下。
言归正传,找到错误信息只是第一步,得基于日志进行分析具体问题,而接近问题
分析错误
第一种猜测:认为 S2 API出问题了,然后去S2服务器看请求日志和load 负载都不高,内存也没有问题。那么可以排除。
第二种猜测:Yii2 S1 站点代码出问题了,当第一个人反馈的我还有这种猜测,但是随着其他人反馈我知道,肯定不是代码问题。排除
这个时候我心里其实知道一定是流量"大"导致的,因为当天把老系统10来个域名切换到新的系统了,那么就会导致新的系统访问量增加。这是今天系统唯一变化的地方,在排查错误过程中有个原则就是 本来是好的,现在不好了,那么从好到不好这期间应该有什么东西变化了,这个变化的就是我们要第一优先级考虑的线索。
临时处理方法:问题解决不了,但是我们不能一直有时间去慢慢排查,因为每天的运营推广费用总体都有几十万了,那么我们就做一个动作:将今天切换的域名切回老系统,先让业务恢复。这么操作之后临时恢复了可以访问。
但是这只是为我们争取到了时间,让我们有更多的时间排查错误,那么继续猜测下去。
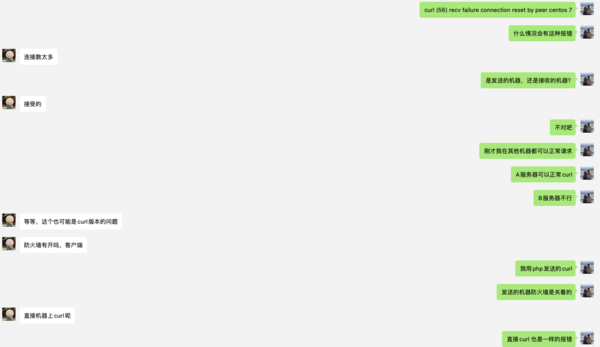
第三个猜测:既然S2 API 服务没问题,那么问题应该在S1上面,我就在S1服务使用命令 curl 访问了下,报错同样的(如下图),这时候见鬼了,我就跑到另外一台服务器暂时叫S3 使用同样的curl 可以访问。此时就可以完全确定 S1 服务的问题,无论什么问题肯定这台机器出问题了


定位问题
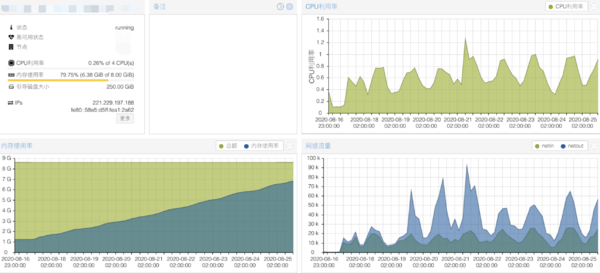
基于第三个猜测的方向,定位问题情况,那么我们就可以在S1上面更加仔细的排查了,我看了机器的各种硬件指标是正常的(CPU LOAD,内存,网卡的流量),如下图一切正常,完全访问没压力(下图中的内存使用率不对,因为没有加上 buffer 的,实际内存还剩余很多)。这个时候陷入了僵局,
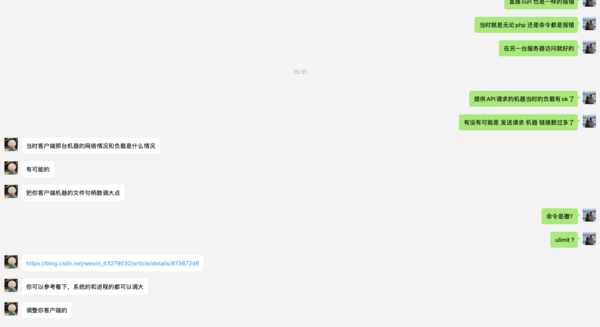
的确是很久不做运维一线工作了,敏感度不够,我就找了一个运维朋友问了下,真的是一语惊醒梦中人,我结合今天的动作增加流量 我觉得他的说法是对的,然后我就按照这个思路去验证。
解决问题
基于我运维朋友的指点,我看了S1的文件句柄真的很小,就是1024,我看了当时的请求量比平时多了3倍,所以不够很正常,我就把句柄数设置更大了,很多朋友说 这样只是修改了优化参数,如何验证咧?
验证问题
问题是必然要被解决的,既然有了新系统那么必然是要切换的,不把问题解决就没办法完全切过去。我就让把今天添加的域名一点点的加,看看请求户会不会出现问题,有点压力测试的感觉。直接我们说结果:把所有域名切换到新系统,并还多加了几个域名 发现 S1服务器 屁事都没有,压力完全没有,我就说嘛在我的印象中一台 4核8G 服务器 怎么承受这点压力都受不住了。
总结
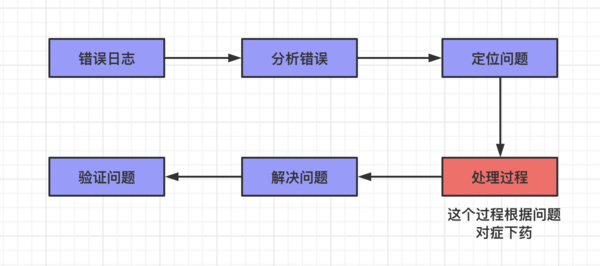
在这个过程大家可以看到一个大致的排查错误的一个方式方法 如下图。这里面有一个过程有点反过来的感觉:解决问题->验证问题,大部分思维应该是 验证问题->解决问题 。这里面是因为我们前面临时解决问题了,导致没办法直接验证,而要先把问题解决了在验证
不足之处
报警机制不够完善,导致没有第一时间报警
服务器初始化做的不够完善,导致服务器优化配置出问题
后续基于以上的不足我们这边会完善运维系统,为企业提供高可用服务保驾护航

